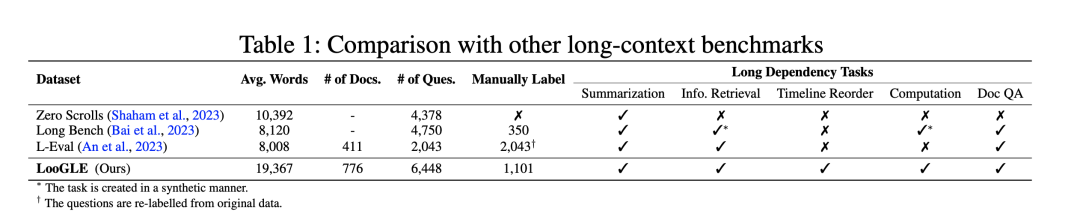
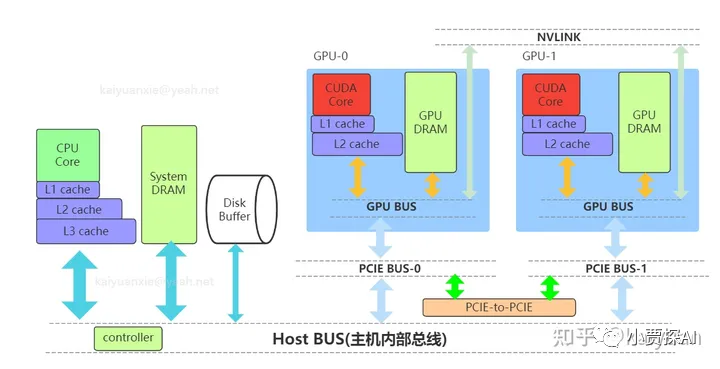
Post Views: 167 在人工智能大模型训练的过程中,常常会面临显存资源不足的情况,其中包括但不限于以下两个方面:1.经典错误:CUDA out of memory. Tried to allocate ...;2.明明报错信息表明显存资源充足,仍然发生 OOM 问题。为了深入理解问题的根源并寻求解决方案,必须对系统内存架构以及显存管理机制进行进一步的探究。本文将为读者带来对这些基础知识的
Post Views: 48 众所周知,大模型的训练需要大量的显存资源,单卡很容易就爆了,于是就有了单机多卡、多机多卡的训练方案。本文主要是介绍如何使用deepspeed框架做多机多卡的分布式训练。 由于PyTorch、NVIDIA、CUDA等运行环境搭建也是很繁琐,所以这次我们用docker来快速搭建,但是deepspeed多机训练是通过ssh来通讯的,不同服务器的docker容器