书生·浦语大模型-XTuner大模型单卡微调实战
- AIGC
- 2024-05-15
- 132热度
- 0评论
一、 Finetune简介
增量预训练微调:让基座模型学习到一些新知识,如某个垂类领域的常识
指令跟随微调:让模型学会对话模板,根据人类指令进行对话

二、 数据处理
1、 为了让LLM知道什么时候开始/结束一段话,实际训练时需要对数据添加起始符BOS和结束符EOS。大多数模型使用<s>作为起始符,使用</s>作为结束符。
2、 增量预训练微调:将system和input置空,把数据放入output,仍然计算assistant部分的损失
3、 指令跟随微调
(1)微调阶段,实际对话中的三种角色(对话模板):System + User + Assistant
(2)训练时,只会对答案(Output)部分计算loss
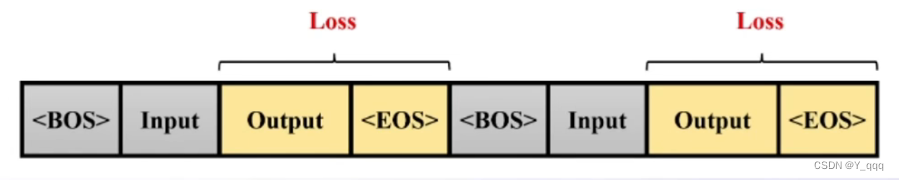
(3)模板和推理时保持一致,对数据添加相应的对话模板

三、 原理 LoRA & QLoRA
1、 LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
(1)LLM的参数量主要集中在模型的Linear,训练这些参数会耗费大量的显存。LoRA通过在原本的Linear旁,新增一个支路,包含两个连续的小Linear,新增的这个支路通常叫做Adapter。Adapter的参数量远远小于原来Linear的,能大幅度降低训练的显存消耗。
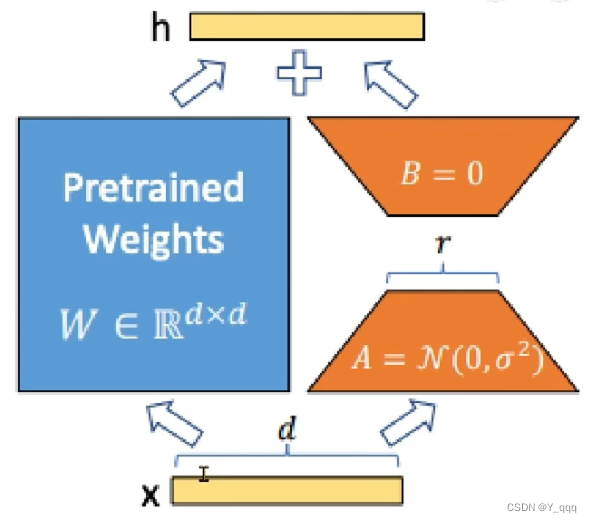
2、 QLoRA:对LoRA的进一步改进
3、 对比
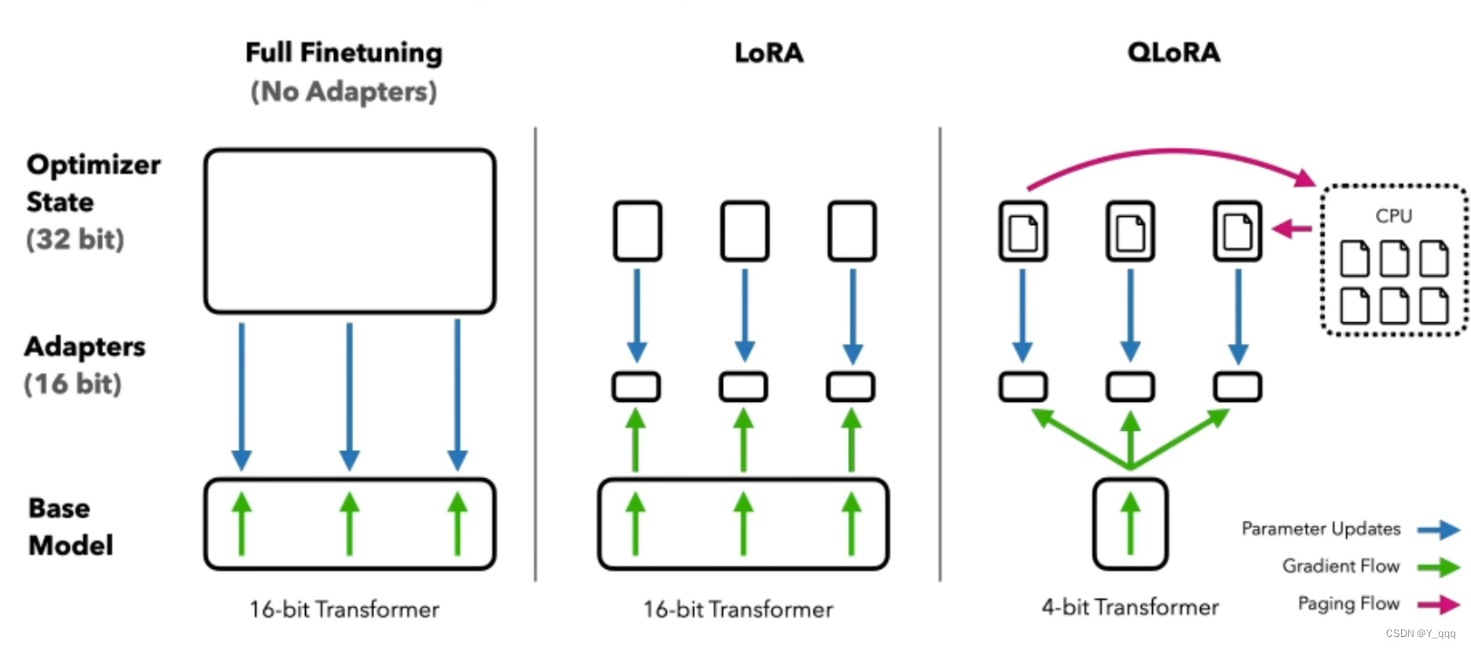
(1)Full Finetuning
a. Base Model参与训练并更新参数
b. 需要保存Base Model中参数的优化器状态
(2)LoRA
a. Base Model只参与Forward
b. 只有Adapter部分Backward更新参数
c. 只需保存Adapter中参数的优化器状态
(3)QLoRA
a. Base Model量化为4-bit
b. 优化器状态在CPU与GPU之间调度
c. Base Model只参与Forward
d. 只有Adapter部分Backward更新参数
e. 只需保存Adapter中参数的优化器状态
四、 XTuner微调框架
XTuner简介
适配多种状态
多种微调算法,覆盖各类SFT场景
适配多种开源生态,支持加载HuggingFace、ModelScope等模型或数据集
自动优化加速,开发者无需关注复杂的显存优化与计算加速细节
适配多种硬件
训练方案覆盖NVIDIA 20系列以上所有显卡
最低只需8GB显存即可微调7B模型
快速上手
数据处理引擎
数据处理流程。开发者可以专注于数据内容,不必耗费精力处理数据格式。
多数据样本拼接
五、 8GB显存玩转LLM
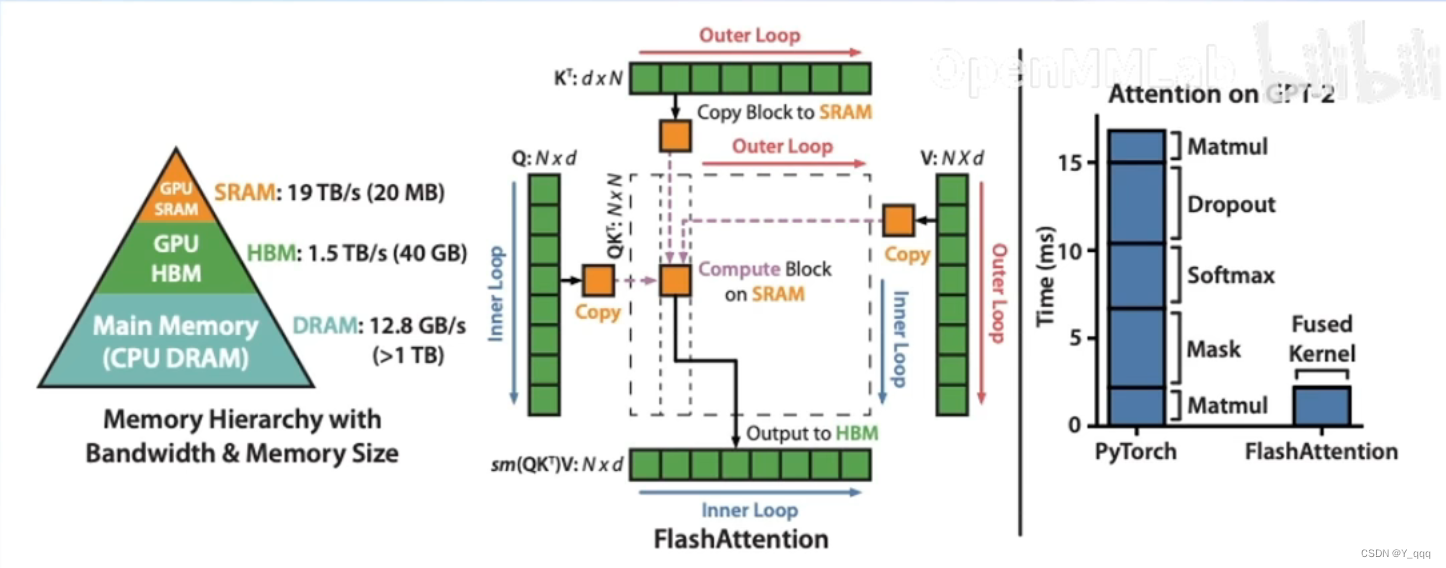
1、 Flash Attention
将Attention计算并行化,避免计算过程中Attention Score NxN的显存占用(训练过程中的N都比较大)
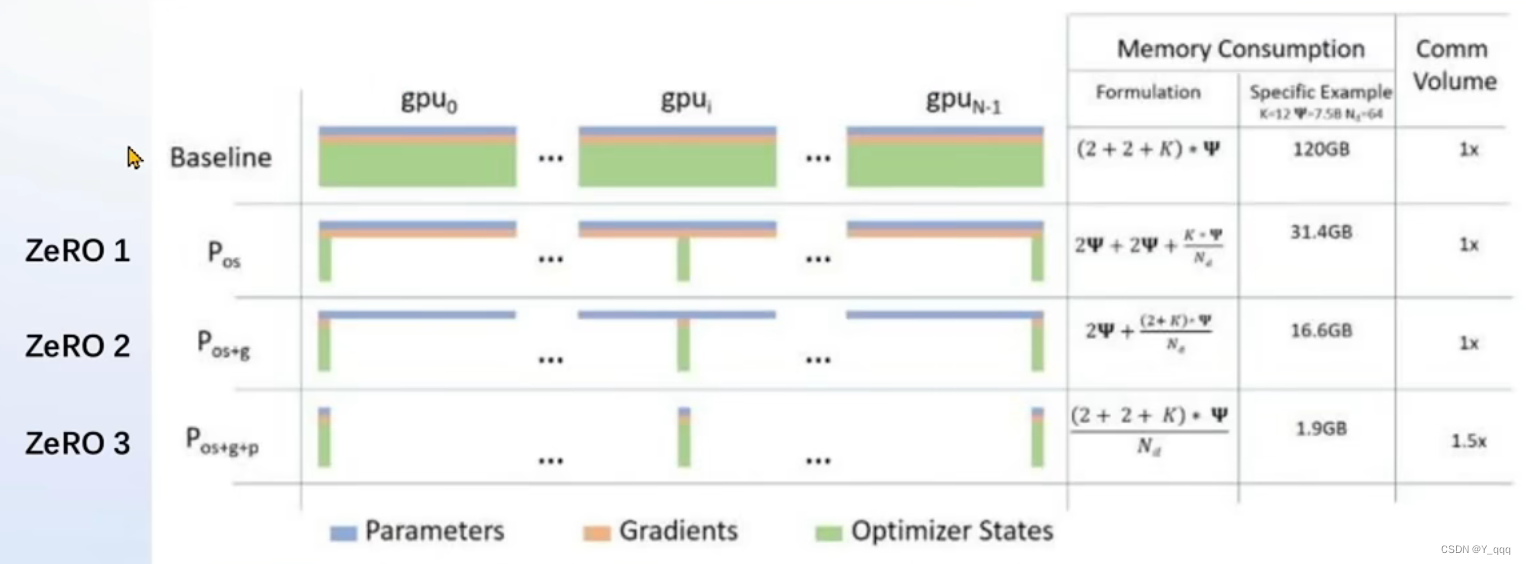
2、 DeepSpeed ZeRO
ZeRO优化,通过将训练过程中的参数,梯度和优化器状态切片保存,能够在多GPU训练时显著节省显存。
除了将训练中间状态切片外,DeepSpeed训练时使用FP16的权重,相较于Pytorch的AMP训练,在单GPU上也能大幅节省显存。
启动:--deepspeed deepspeed_zero2
六、 动手实践
1、 微调配置文件
xtuner提供的开箱即用的配置文件:1
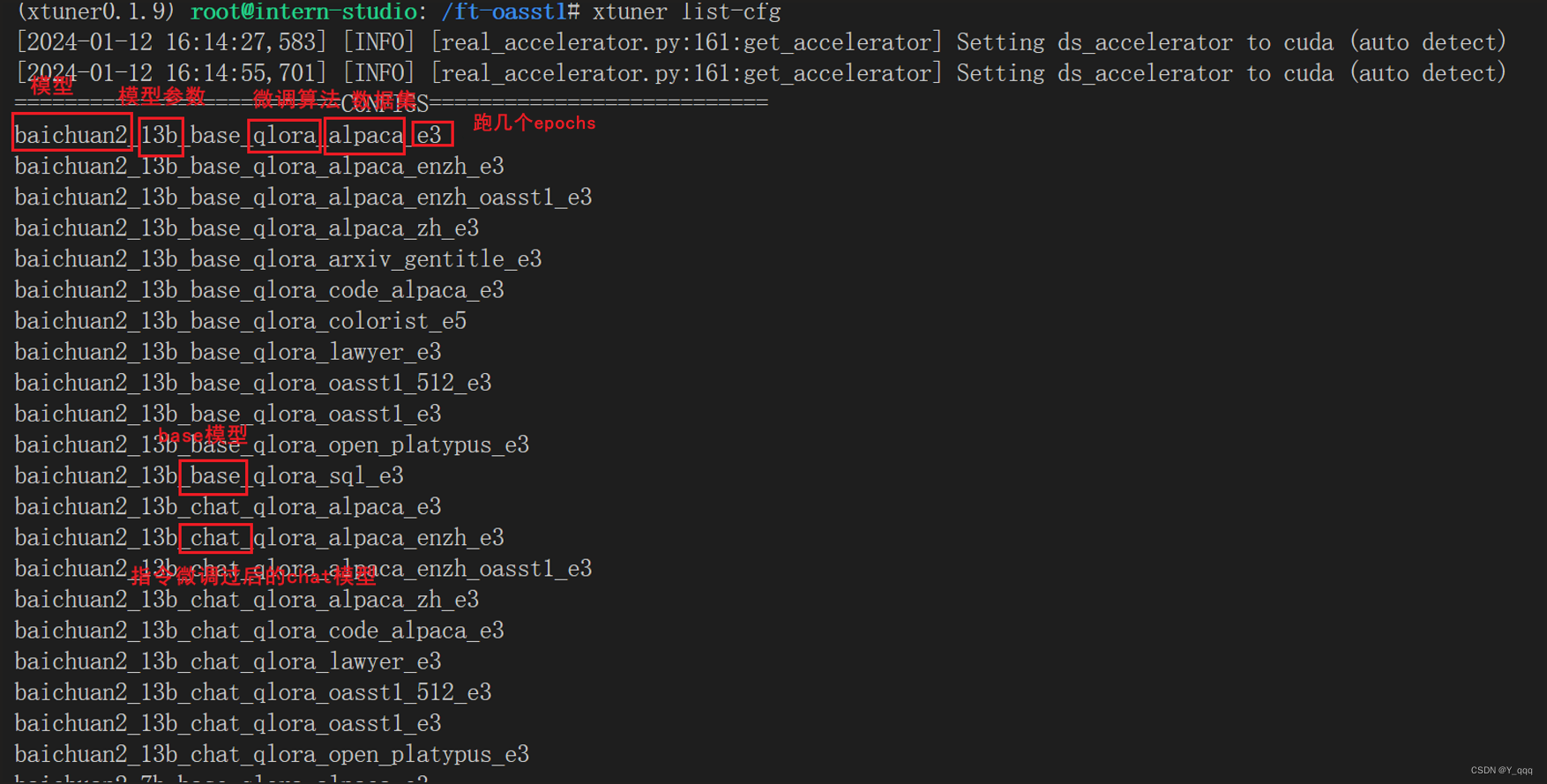
2、配置文件的常用超参

3、 开始微调
(1)训练
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加deepspeed进行训练加速:--deepspeed deepspeed_zero2
(2)将得到的PTH模型转化为HuggingFace模型,生成Adapter文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
hf文件夹即为LoRA模型文件
4、 部署与测试
(1)将huggingFace adapter合并到大语言模型
xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH} --max-shard-size 2GB
(2)与合并后的模型对话
xtuner chat ./merged --prompt-template internlm_chat
4 bit 量化加载:
xtuner chat ./merged --bits 4 --prompt-template internlm_chat
七、 补充:用MS-Agent数据集赋予LLM以Agent能力
可以调用接口获取实时数据,例如当前天气。
作业!!!
一、 基础作业:构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手
1、 环境准备
2、 数据准备
准备json文件作为本次微调使用的数据集包含50000条数据。

3、 配置准备
(1)下载模型InternLM-chat-7B
(2)拷贝一个配置文件到当前目录
xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
本例中
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
(3)修改配置文件参数
# PART 1中
#预训练模型存放的位置
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'
#微调数据存放的位置
data_path='/root/personal_assistant/data/personal_assistant.json'
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 2
#最大训练轮数
max_epochs = 3
# 验证的频率
evaluation_freq = 90
# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = ["请介绍一下你自己" ,"请做一下自我介绍"]
# PART 3中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data path))
dataset_map_fn=None
4、 微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
5、 微调后参数转换/合并
(1)训练后的pth格式参数转Hugging Face格式
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
(2)Merge模型参数
xtuner convert merge $NAME_OR_PATH_TO_LLM $NAME_OR_PATH_TO_ADAPTER $SAVE_PATH --max-shard-size 2GB
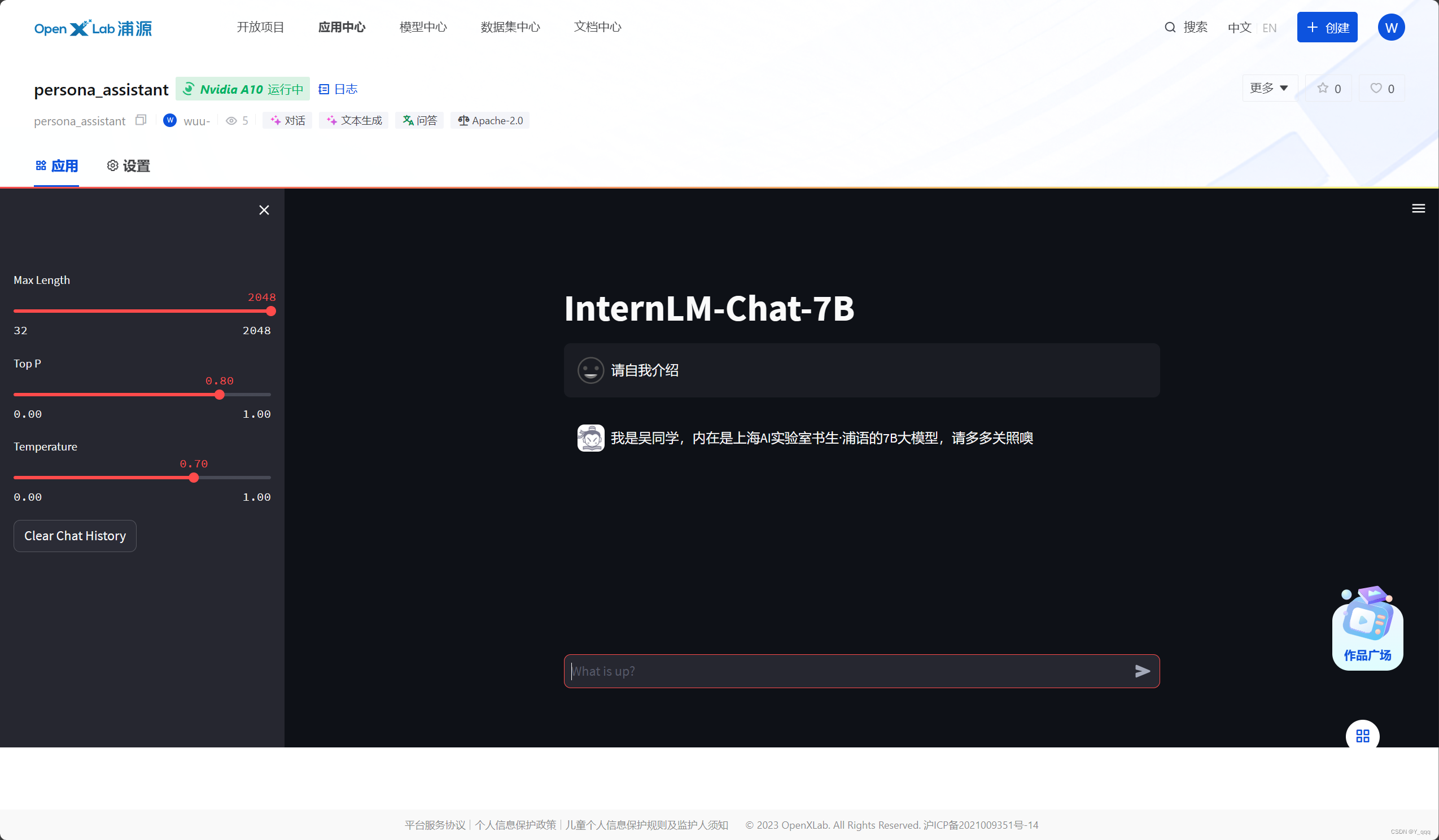
6、效果
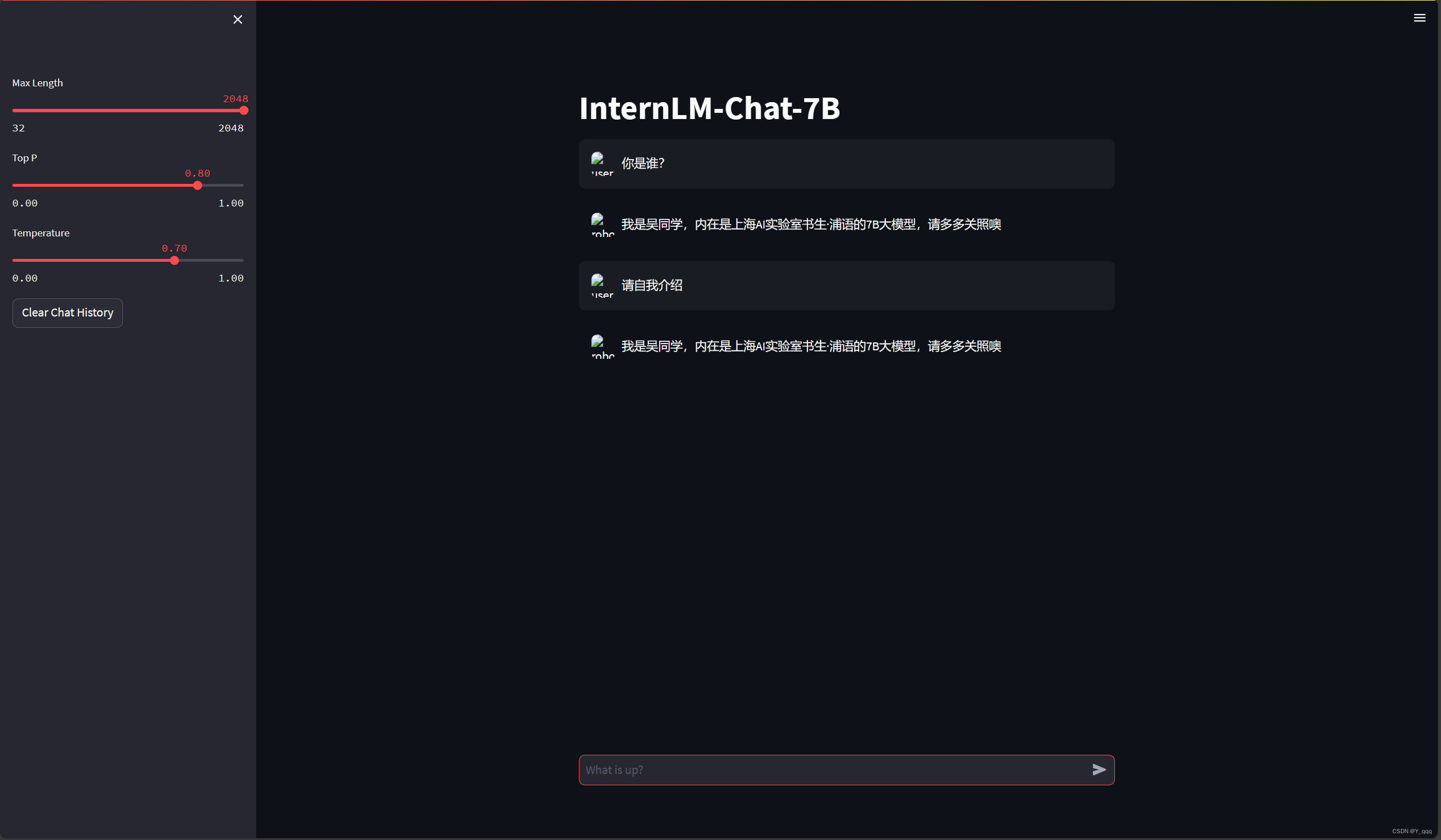
二、 进阶作业:
1、将训练好的Adapter模型权重上传到 OpenXLab平台:wuu-/personal_assistant_hf
合并后:个人助手(wuu-/personal_assistant)
2、将训练好后的模型应用部署到 OpenXLab 平台:wuu-/persona_assistant